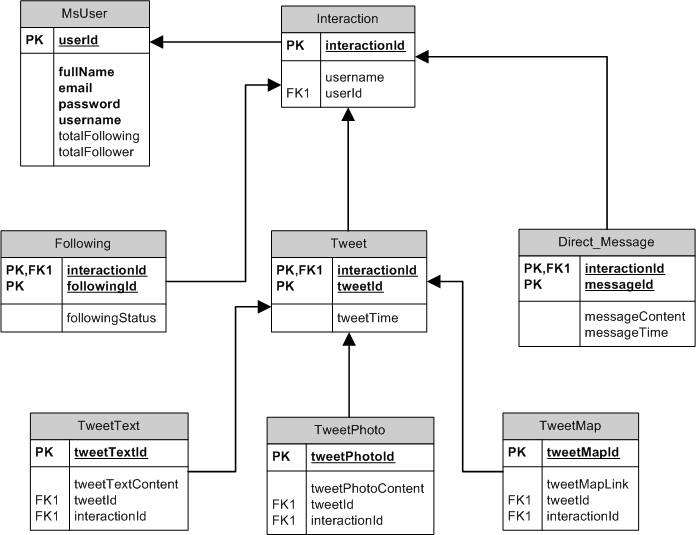
 Keterangan dari gambar ERD diatas :
Keterangan dari gambar ERD diatas :
Tabel MsUser menampung data-data user seperti userId, fullName, email, password, username, totalFollowing, dan totalFollower.
Tabel Interaction merupakan table yang dapat berhubungan dengan table MsUser, Following, Tweet, DirectMessage. Tabel Interaction menggambarkan interaksi-interaksi yang dapat dilakukan oleh user seperti MsUser, Following, Tweet, DirectMessage.
Tabel Following berisi interactionId, followingId, followingStatus. Tabel ini menggambarkan bahwa user dapat melakukan following dengan user lain serta mengetahui status apakah sudah following dengan user lain atau belum.
Tabel Tweet berisi interactionId, tweetId, tweetTime. Tabel ini menggambarkan bahwa user dapat melakukan jenis interaksi berupa tweet dan mengetahui waktu saat user melakukan suatu tweet. Di samping itu, tabel Tweet juga terhubung dengan tabel tweetText, tweetPhoto, tweetMap. Hal tersebut menunjukkan bahwa user dapat melakukan tweet seperti text, photo dan lokasi dari user.
Tabel Direct_Message terdiri dari interactionId, messageId, messageContent, dan messageTime. Tabel ini menunjukkan bahwa interaksi lain yang dapat dilakukan oleh user yaitu mengirim dan menerima pesan kepada user lain dalam bentuk direct message.
Tabel TweetText terdiri dari tweetTextId, tweetTextContent, tweetId, dan interactionId. Tabel ini berfungsi untuk menampung tweet-tweet yang dilakukan oleh user dalam hal ini text.
Tabel TweetPhoto terdiri dari tweetPhotoId, tweetPhotoContent, tweetId, dan interactionId. Tabel ini berfungsi untuk menampung tweet-tweet yang dilakukan oleh user dalam hal ini photo.
Tabel TweetMap terdiri dari tweeMapId, tweetMapLink, tweetId, dan interactionId. Tabel ini berfungsi untuk menampung tweet-tweet yang dilakukan oleh user berupa lokasi user.
{kind=link}